
Amazon S3 Tables の Iceberg テーブルにS3上のデータファイルをロードしてみる #AWSreInvent

AWS事業本部コンサルティング部の石川です。本日は、Amazon S3 Tables のIcebergテーブルにサンプルデータ「SSB」のcustomerデータ(GZIP圧縮100MB、300万レコード)をロードする方法を紹介します。データファイルは以下のブログで紹介しているファイルです。
なお、先日のブログでは、Amazon S3 Tables を AWS Glue 用いてNamespaceとテーブルの作成、データ追加・削除までやってみました。基本的な動きは、こちらのブログを参照してください。
AWS Glue でNamespaceとテーブルの作成、データ追加
以降の検証は、US East (N. Virginia) us-east-1 リージョンで実施しました。
マネジメントコンソールからテーブルバケットを作成
[Table buckets New ]のメニューを選び、[Create table bucket]を押します。
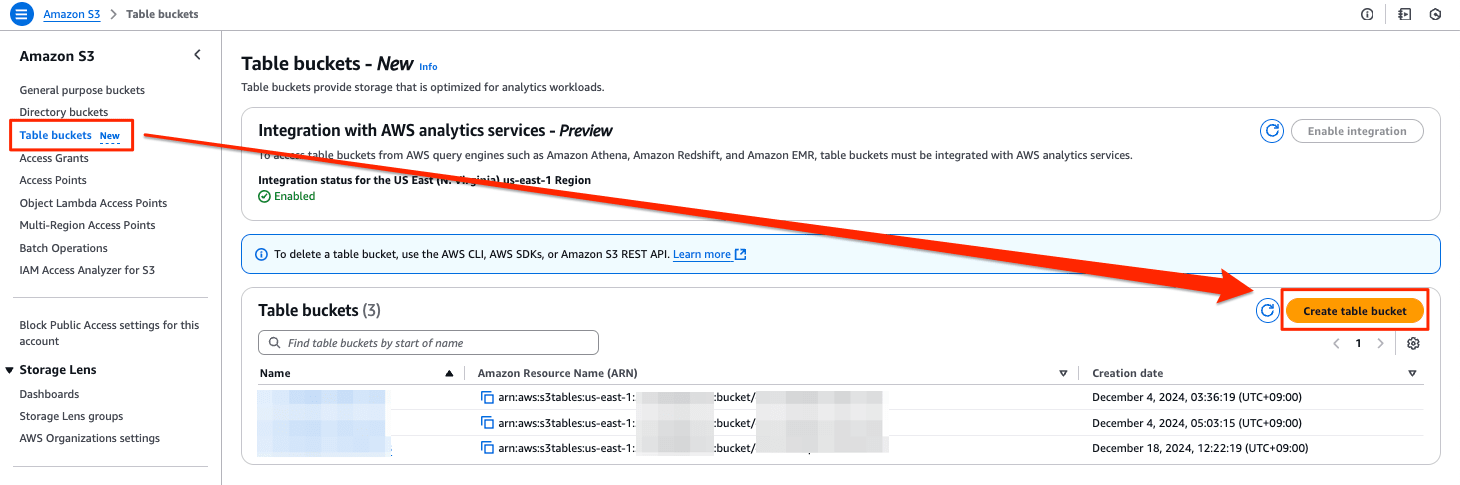
Table bucket nameを入力して、[Create table bucket]を押します。

Glue ETL ジョブの作成
S3 Tables用のランタイムのダウンロード
以下のリンクからダウンロードしてください。
s3-tables-catalog-for-iceberg-runtime-0.1.3.jar
ジョブの設定
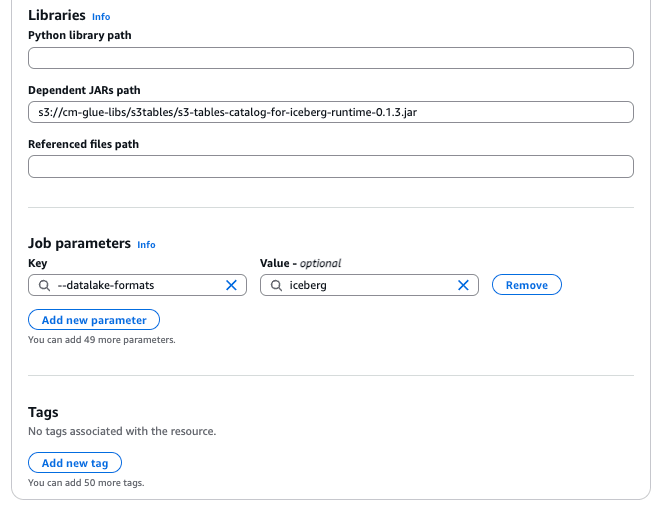
Job details タブの各項目に以下の設定を追加してください。
- Glue version: Glue 5.0
- Worker type: G 1X
- Requested number of workers: 2
- Dependent JARs path:
s3://<your_bucket>/<your_key>/s3-tables-catalog-for-iceberg-runtime-0.1.3.jar - Job parameters:
--datalake-formatsiceberg
ソースコードの解説
今後、普通のS3上のSpark Sessionと別に必要になるため、S3 Tables 用の Spark Session 作成用の関数を作成しました。
# Create Spark Session for S3 Tables
def build_spark_session_s3t(namespace, warehouse_arn):
conf = SparkConf()
conf.set(f"spark.sql.catalog.{namespace}", "org.apache.iceberg.spark.SparkCatalog")
conf.set(f"spark.sql.catalog.{namespace}.warehouse", warehouse_arn)
conf.set(f"spark.sql.catalog.{namespace}.catalog-impl", "software.amazon.s3tables.iceberg.S3TablesCatalog")
conf.set(f"spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
sparkContext = SparkContext(conf=conf)
glueContext = GlueContext(sparkContext)
# Spark Session
spark = glueContext.spark_session
return(spark)
S3上のパイプ区切り文字のデータとshemaの型定義によって、Dataframeを作成します。最後の2行は、スキーマ定義とデータのデバック用の表示です。
# Create DataFrame from S3 Object
schema = StructType([
StructField("c_custkey", IntegerType(), True),
StructField("c_name", StringType(), True),
StructField("c_address", StringType(), True),
StructField("c_city", StringType(), True),
StructField("c_nation", StringType(), True),
StructField("c_region", StringType(), True),
StructField("c_phone", StringType(), True),
StructField("c_mktsegment", StringType(), True)
])
input_path = "s3://cm-datalake-20241220/ssbgz/customer/customer0002_part_00.gz"
df = spark.read.option("delimiter", "|").schema(schema).csv(input_path)
df.printSchema()
df.show()
この部分で、S3 Table 上の customerに対して、Dataframe(tmp_customer)のデータをINSERT INTO SELECT でコピーします。
# Insert records into Iceberg table in S3 Tables
df.createOrReplaceTempView("tmp_customer")
spark.sql( """ INSERT INTO s3tablesbucket.cm_namespace.`customer` SELECT * FROM tmp_customer""" )
ソースコード(全体)
Scriptタブに以下のコードをコピーします。warehouseには、作成したS3 Tablesのarnに変更してください。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from pyspark.conf import SparkConf
from awsglue.job import Job
from pyspark.sql.functions import *
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
# Create Spark Session for S3 Tables
def build_spark_session_s3t(namespace, warehouse_arn):
conf = SparkConf()
conf.set(f"spark.sql.catalog.{namespace}", "org.apache.iceberg.spark.SparkCatalog")
conf.set(f"spark.sql.catalog.{namespace}.warehouse", warehouse_arn)
conf.set(f"spark.sql.catalog.{namespace}.catalog-impl", "software.amazon.s3tables.iceberg.S3TablesCatalog")
conf.set(f"spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
sparkContext = SparkContext(conf=conf)
glueContext = GlueContext(sparkContext)
# Spark Session
spark = glueContext.spark_session
return(spark)
warehouse_arn = "arn:aws:s3tables:us-east-1:123456789012:bucket/cm-namespace-20241218"
spark = build_spark_session_s3t("s3tablesbucket", warehouse_arn)
# Create DataFrame from S3 Object
schema = StructType([
StructField("c_custkey", IntegerType(), True),
StructField("c_name", StringType(), True),
StructField("c_address", StringType(), True),
StructField("c_city", StringType(), True),
StructField("c_nation", StringType(), True),
StructField("c_region", StringType(), True),
StructField("c_phone", StringType(), True),
StructField("c_mktsegment", StringType(), True)
])
input_path = "s3://cm-datalake-20241220/ssbgz/customer/customer0002_part_00.gz"
df = spark.read.option("delimiter", "|").schema(schema).csv(input_path)
df.printSchema()
df.show()
# Create namespace in S3 Tables
spark.sql( """ CREATE NAMESPACE IF NOT EXISTS s3tablesbucket.cm_namespace """)
# Delete in S3 Tables
spark.sql( """ DELETE FROM s3tablesbucket.cm_namespace.`customer` """)
# Create Table using Iceberg in S3 Tables
spark.sql( """ CREATE TABLE IF NOT EXISTS s3tablesbucket.cm_namespace.`customer` (c_custkey INT, c_name STRING, c_address STRING, c_city STRING, c_nation STRING, c_region STRING, c_phone STRING, c_mktsegment STRING) USING iceberg """)
# Use Namespace
spark.sql( """ USE s3tablesbucket.cm_namespace """)
# Show Tables
spark.sql( """ SHOW TABLES """).show()
# Insert records into Iceberg table in S3 Tables
df.createOrReplaceTempView("tmp_customer")
spark.sql( """ INSERT INTO s3tablesbucket.cm_namespace.`customer` SELECT * FROM tmp_customer""" )
# Read from Iceberg table in S3 Tables
spark.sql(""" SELECT * FROM s3tablesbucket.cm_namespace.`customer` """).show()
実行結果
上記のGlue ETLジョブを実行したログファイルです。上がS3上のデータファイルを読み込んだDataframeの表示です。一方、下がS3 Tables のテーブル(customer)のレコードの表示です。

Amazon Athenaのクエリエディタで確認します。レコードが追加されていることが確認できます。

次にレコード数を確認しました。300万レコードすべてロードできたことが確認できます。また、Data scannedが表示されていないということは、メタデータだけでデータをスキャンしなかった(利用費はかからない)ということを表します。

最後に
今日は、将来的な利用も鑑み、S3 Tables 用の Spark Session 作成用の関数を作成しました。S3上のファイルをDataframeにロードするときに、S3 Tables 用のSparkSessionをそのまま使ってよいのか迷いましたが、そのまま使えたので流用しました。このあたりのベストプラクティスは今後の課題です。
AWS Glue ETL ジョブを使用することで、S3上のデータを効率的にS3 Tables上のIcebergフォーマットのテーブルに取り込むことができます。この方法は、実務での活用を見据えた実践的なアプローチであり、大規模なデータセットの処理や分析に適しています。






![AWS Control TowerのメンバーアカウントをTerraformで作成する [Not AFT]](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-fff4d7e7c3509d1ffcc67578673c5f00/056494cb8aea27071cd8ed8a870bda83/aws-control-tower)
